Using Python Regex To Extract Certain Urls From Text
So I have the HTML from an NPR page, and I want to use regex to extract just certain URLs for me (these call the URLs to specific stories nested within the page). The actual links
Solution 1:
Through a tool which is specially designed for parsing html and xml files [BeautifulSoup],
>>> from bs4 import BeautifulSoup
>>> s = """<a href="http://www.npr.org/blogs/parallels/2014/11/11/363018388/how-the-islamic-state-wages-its-propaganda-war">
<a href="http://www.npr.org/blogs/thetwo-way/2014/11/11/363309020/asked-to-stop-praying-alaska-school-won-t-host-state-tournament">
<a href="http://www.npr.org/2014/11/11/362817642/a-marines-parents-story-their-memories-that-you-should-hear">
<a href="http://www.npr.org/blogs/thetwo-way/2014/11/11/363288744/comets-rugged-landscape-makes-landing-a-roll-of-the-dice">
<a href="http://www.npr.org/blogs/thetwo-way/2014/11/11/363293514/for-dyslexics-a-font-and-a-dictionary-that-are-meant-to-help">""">>> soup = BeautifulSoup(s) # or pass the file directly into BS like >>> soup = BeautifulSoup(open('/Users/shannonmcgregor/Desktop/npr.txt'))>>> atag = soup.find_all('a')
>>> links = [i['href'] for i in atag]
>>> import re
>>> for i in links:
if re.match(r'.*(parallels|thetwo-way|a-marines).*', i):
print(i)
http://www.npr.org/blogs/parallels/2014/11/11/363018388/how-the-islamic-state-wages-its-propaganda-war
http://www.npr.org/blogs/thetwo-way/2014/11/11/363309020/asked-to-stop-praying-alaska-school-won-t-host-state-tournament
http://www.npr.org/2014/11/11/362817642/a-marines-parents-story-their-memories-that-you-should-hear
http://www.npr.org/blogs/thetwo-way/2014/11/11/363288744/comets-rugged-landscape-makes-landing-a-roll-of-the-dice
http://www.npr.org/blogs/thetwo-way/2014/11/11/363293514/for-dyslexics-a-font-and-a-dictionary-that-are-meant-to-helpSolution 2:
You can use re.search function to match the regex in the line and prints the line if it matches as
>>>file = open('/Users/shannonmcgregor/Desktop/npr.txt', 'r')>>>for line in file:...if re.search('<a href=[^>]*(parallels|thetwo-way|a-marines)', line):...print linewill give an output as
<ahref="http://www.npr.org/blogs/parallels/2014/11/11/363018388/how-the-islamic-state-wages-its-propaganda-war"><ahref="http://www.npr.org/blogs/thetwo-way/2014/11/11/363309020/asked-to-stop-praying-alaska-school-won-t-host-state-tournament"><ahref="http://www.npr.org/2014/11/11/362817642/a-marines-parents-story-their-memories-that-you-should-hear"><ahref="http://www.npr.org/blogs/thetwo-way/2014/11/11/363288744/comets-rugged-landscape-makes-landing-a-roll-of-the-dice"><ahref="http://www.npr.org/blogs/thetwo-way/2014/11/11/363293514/for-dyslexics-a-font-and-a-dictionary-that-are-meant-to-help">Solution 3:
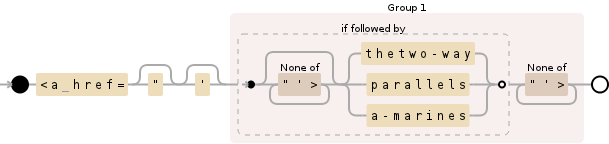
You can do this by using a lookahead:
<a href="?\'?((?=[^"\'>]*(?:thetwo\-way|parallels|a\-marines))[^"\'>]+)
{kind=link}
Post a Comment for "Using Python Regex To Extract Certain Urls From Text"